多道程序与协作式调度¶
本节导读¶
上一节我们已经介绍了任务管理的一些基本结构,这一节我们主要介绍进程切换相关的具体实现。
多道程序背景与 yield 系统调用¶
还记得第二章中介绍的批处理系统的设计初衷吗?它是注意到 CPU 并没有一直在执行应用程序,在一个应用程序运行结束直到下一个应用程序开始运行的这段时间,可能需要操作员取出上一个程序的执行结果并手动进行程序卡片的替换,这段空档期对于宝贵的 CPU 计算资源是一种巨大的浪费。于是批处理系统横空出世,它可以自动连续完成应用的加载和运行,并将一些本不需要 CPU 完成的简单任务交给廉价的外围设备,从而让 CPU 能够更加专注于计算任务本身,大大提高了 CPU 的利用率。
尽管 CPU 一直在跑应用了,但是其利用率仍有上升的空间。随着应用需求的不断复杂,有的时候会在内核的监督下访问一些外设,它们也是计算机系统的另一个非常重要的组成部分,即 输入/输出 (I/O, Input/Output) 。CPU 会将请求和一些附加的参数写入外设,待外设处理完毕之后, CPU 便可以从外设读到请求的处理结果。比如在从作为外部存储的磁盘上读取数据的时候,CPU 将要读取的扇区的编号以及读到的数据放到的物理地址传给磁盘,在磁盘对请求进行调度并完成数据拷贝之后,就能在物理内存中看到要读取的数据。
在一个应用对外设发出了请求之后,它不能立即向下执行,而是要等待外设将请求处理完毕并拿到完整的处理结果之后才能继续。那么如何知道外设是否已经完成了请求呢?通常外设会提供一个可读的寄存器记录它目前的工作状态,于是 CPU 需要不断原地循环读取它直到它的结果显示设备已经将请求处理完毕了,才能向下执行。然而,外设的计算速度和 CPU 相比可能慢了几个数量级,这就导致 CPU 有大量时间浪费在等待外设这件事情上,这段时间它几乎没有做任何事情,也在一定程度上造成了 CPU 的利用率不够理想。
我们暂时考虑 CPU 只能 单方面 通过读取外设提供的寄存器来获取外设请求处理的状态。多道程序的思想在于:内核同时管理多个应用。如果外设处理的时间足够长,那我们可以先进行任务切换去执行其他应用,在某次切换回来之后,应用再次读取设备寄存器,发现请求已经处理完毕了,那么就可以用拿到的完整的数据继续向下执行了。这样的话,只要同时存在的应用足够多,就能保证 CPU 不必浪费时间在等待外设上,而是几乎一直在进行计算。这种任务切换,是通过应用进行一个名为 sys_yield 的系统调用来实现的,这意味着它主动交出 CPU 的使用权给其他应用。
这正是本节标题的后半部分“协作式”的含义。一个应用会持续运行下去,直到它主动调用 sys_yield 来交出 CPU 使用权。内核将很大的权力下放到应用,让所有的应用互相协作来最终达成最大化 CPU 利用率,充分利用计算资源这一终极目标。在计算机发展的早期,由于应用基本上都是一些简单的计算任务,且程序员都比较遵守规则,因此内核可以信赖应用,这样协作式的制度是没有问题的。
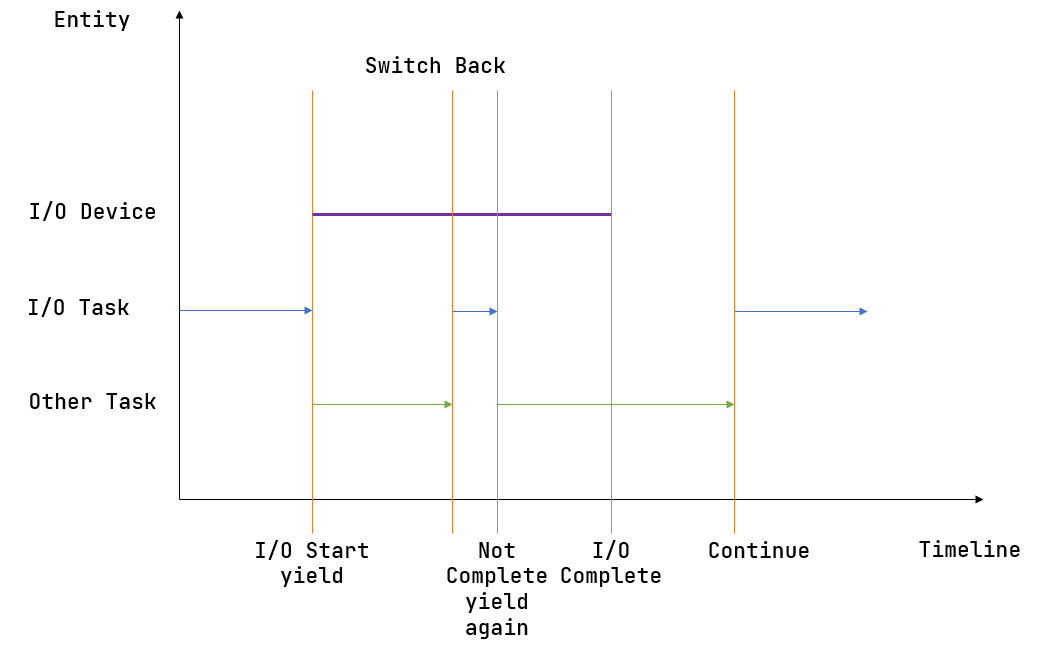
上图描述了一种多道程序执行的典型情况。其中横轴为时间线,纵轴为正在执行的实体。开始时,某个应用(蓝色)向外设提交了一个请求,随即可以看到对应的外设(紫色)开始工作。但是它要工作相当长的一段时间,因此应用(蓝色)不会去等待它结束而是会调用 sys_yield 主动交出 CPU 使用权来切换到另一个应用(绿色)。另一个应用(绿色)在执行了一段时间之后调用了 sys_yield ,此时内核决定让应用(蓝色)继续执行。它检查了一下外设的工作状态,发现请求尚未处理完,于是再次调用 sys_yield 。然后另一个应用(绿色)执行了一段时间之后 sys_yield 再次切换回这个应用(蓝色),这次的不同是它发现外设已经处理完请求了,于是它终于可以向下执行了。
上面我们是通过“避免无谓的外设等待来提高 CPU 利用率”这一切入点来引入 sys_yield 。但其实调用 sys_yield 不一定与外设有关。随着内核功能的逐渐复杂,我们还会遇到很多其他类型的需要等待其完成才能继续向下执行的事件,我们都可以立即调用 sys_yield 来避免等待过程造成的浪费。
注解
sys_yield 的缺点
请读者思考一下, sys_yield 存在哪些缺点?
当应用调用它主动交出 CPU 使用权之后,它下一次再被允许使用 CPU 的时间点与内核的调度策略与当前的总体应用执行情况有关,很有可能远远迟于该应用等待的事件(如外设处理完请求)达成的时间点。这就会造成该应用的响应延迟不稳定,有可能极高。比如,设想一下,敲击键盘之后隔了数分钟之后才能在屏幕上看到字符,这已经超出了人类所能忍受的范畴。
但也请不要担心,我们后面会有更加优雅的解决方案。
我们给出 sys_yield 的标准接口:
/// 功能:应用主动交出 CPU 所有权并切换到其他应用。
/// 返回值:总是返回 0。
/// syscall ID:124
int sys_yield();
然后是用户库对应的实现和封装:
// user/lib/syscall.c
int sched_yield()
{
return syscall(SYS_sched_yield);
}
接下来我们介绍内核应如何实现该系统调用。
进程的切换¶
下面我们介绍本章的最最最重要的进程切换(调度)问题。
进程的切换?¶
说到切换,大家肯定对第二章中异常产生后,从U态切换到S态的流程历历在目。实际上,进程的切换和它十分类似。大家可以类比一下,第二章我们是从进程1—>内核态处理异常—>进程1。那我们完全可以把整个流程转换为进程1–>内核切换–>进程2–>切换–>进程1来实现执行流的切换,并且保证中途的保存和恢复不出错呀!当然这么做会比较复杂,我们的处理方式更加复古一点,但是思路基本是一样的。回顾一下进程的PCB结构体中两个用于切换的结构体成员:
1struct trapframe *trapframe;
2struct context context;
trapframe大家在第二章已经和它打过交到了。那么context这个结构体又记录了什么呢?
1// os/trap.h
2
3// Saved registers for kernel context switches.
4struct context {
5 uint64 ra;
6 uint64 sp;
7 // callee-saved
8 uint64 s0;
9 uint64 s1;
10 uint64 s2;
11 uint64 s3;
12 uint64 s4;
13 uint64 s5;
14 uint64 s6;
15 uint64 s7;
16 uint64 s8;
17 uint64 s9;
18 uint64 s10;
19 uint64 s11;
20};
它相比trapframe,只记录了寄存器的信息。聪明的你可能已经发现它们都是被调用者保存的寄存器。在切换的核心函数swtch(注意拼写)之中,就是对这个结构体进行了操作:
1# Context switch
2#
3# void swtch(struct context *old, struct context *new);
4#
5# Save current registers in old. Load from new.
6
7.globl swtch
8
9# a0 = &old_context, a1 = &new_context
10
11swtch:
12 sd ra, 0(a0) # save `ra`
13 sd sp, 8(a0) # save `sp`
14 sd s0, 16(a0)
15 sd s1, 24(a0)
16 sd s2, 32(a0)
17 sd s3, 40(a0)
18 sd s4, 48(a0)
19 sd s5, 56(a0)
20 sd s6, 64(a0)
21 sd s7, 72(a0)
22 sd s8, 80(a0)
23 sd s9, 88(a0)
24 sd s10, 96(a0)
25 sd s11, 104(a0)
26
27 ld ra, 0(a1) # restore `ra`
28 ld sp, 8(a1) # restore `sp`
29 ld s0, 16(a1)
30 ld s1, 24(a1)
31 ld s2, 32(a1)
32 ld s3, 40(a1)
33 ld s4, 48(a1)
34 ld s5, 56(a1)
35 ld s6, 64(a1)
36 ld s7, 72(a1)
37 ld s8, 80(a1)
38 ld s9, 88(a1)
39 ld s10, 96(a1)
40 ld s11, 104(a1)
41
42 ret # return to new `ra`
为什么只切换这些寄存器就能实现一个切换的效果呢?这是因为执行了swtch切换状态之后,切换的目标进程恢复了保存在context之中的寄存器,并且sp寄存器也指向了它自己栈的位置,ra指向自己测例代码的位置而不是之前函数的位置,这已经足够其从切换出去的位置继续执行了(切换的过程可以视为一次函数调用)。因为真正切换swtch都在内核态发生,也无需记录更多的数据。
- 总结一下,swtch函数干了这些事情:
执行流:通过切换 ra
堆栈:通过切换 sp
寄存器: 通过保存和恢复被调用者保存寄存器。调用者保存寄存器由编译器生成的代码负责保存和恢复。
一旦你理解了上述的过程,那么本章剩余内容就会十分简单~~
下面介绍进程切换的具体细节。
idle进程与scheduler¶
大家可能注意到proc.c文件中除了current_proc还记录了一个idle_proc。这个进程是干什么的呢?实际上,idle 进程是第一个进程(boot进程),也是唯一一个永远会存在的进程,它还有一个大家更熟悉的面孔,它就是 os 的 main 函数。
是时候从头开始梳理从机器 boot 到多个用户进程相互切换到底发生了什么了。
1void main() {
2 clean_bss(); // 清空 bss 段
3 trapinit(); // 开启中断
4 batchinit(); // 初始化 app_info_ptr 指针
5 procinit(); // 初始化线程池
6 // timerinit(); // 开启时钟中断,现在还没有
7 run_all_app(); // 加载所有用户程序
8 scheduler(); // 开始调度
9}
可以看到,在main函数完成了一系列的初始化,并且执行了run_all_app加载完了所有测例之后。它就进入了scheduler调度函数。这个函数就完成了一系列的调度工作:
1void
2scheduler(void)
3{
4 struct proc *p;
5
6 for(;;){
7 for(p = pool; p < &pool[NPROC]; p++) {
8 if(p->state == RUNNABLE) {
9 p->state = RUNNING;
10 current_proc = p;
11 swtch(&idle.context, &p->context);
12 }
13 }
14 }
15}
可以看到一旦main进入调度状态就进入一个死循环再也回不去了。。但它也没必要回去,它现在活着的意义就是为了进行进程的调度。在循环中每一次idle进程都会遍历整个进程池来寻找RUNNABLE(就绪)状态的进程并执行swtch函数切换到它。我们这里的scheduler函数就是最普通的调度函数,完全没有考虑优先度以及复杂度。
这里大家要思考一下,这个函数写对了吗?它真的满足我们每次执行遍历一次的要求,而不是写成了每次都从第0个进程开始遍历查找吗?
yield函数的实现¶
yield 函数具体实现如下:
1// os/proc.c
2
3// Give up the CPU for one scheduling round.
4void yield(void)
5{
6 current_proc->state = RUNNABLE;
7 sched();
8}
9
10void sched(void)
11{
12 struct proc *p = curr_proc();
13 swtch(&p->context, &idle.context);
14}
它本质就是主动放弃执行,并把context移交给负责scheduler进程的idle进程。那这个时候 idle 进程在干什么?
idle 线程死循环在了一件事情上:寻找一个 RUNNABLE 的进程,然后切换到它开始执行。当这个进程调用 sched 后,执行流会回到 idle 线程,然后继续开始寻找,如此往复。直到所有进程执行完毕,在 sys_exit 系统调用中有统计计数,一旦 exit 的进程达到用户程序数量就关机。
也就是说,所有进程间切换都需要通过 idle 中转一下。那么可不可以一步到位呢?答案是肯定的,其实 [rust版代码lab3](https://github.com/rcore-os/rCore-Tutorial-v3) 就是采取这种实现:在一个进程退出时,直接寻找下一个就绪进程,然后直接切换过去,没有 idle 的中转。两种实现都是可行的。
在了解这些之后,我们就可以实现协作式调度了,主要是 sys_yeild 系统调用,其实现十分简单,请同学们自行查看 kernel/syscall.c。